Trivia: Body Gesture Generation for Multimodal Conversational Agents
It has been a while since I last returned to this blog. After submitting a paper, I finally have a bit of free time again, so I thought I would start writing here once more. As always, this post was written very much in a stream-of-consciousness style. If the logic suddenly jumps somewhere or something feels hard to follow, feel free to ask me personally. I would be happy to explain.
This time, I want to talk about the story behind our SIGGRAPH ASIA 2024 paper, Body Gesture Generation for Multimodal Conversational Agents. Honestly, this was the topic I wanted to write about first when I started the blog. However, since this work came from a project at my previous company, I was cautious about accidentally discussing confidential details, so I am only writing about it now. I will try to keep the discussion around details already present in the paper while sharing some background stories. For potentially sensitive topics, I will attach publicly available references and make it clear that this post is based only on externally released information.
Some people, perhaps many people, may have looked at this paper and thought of it simply as “a network that generates motion from speech input.” I also got the impression that some people did not even consider it a computer animation paper. However, what I want to emphasize is that this work was an attempt to address a problem that had not been explored very deeply in animation research. Rather than generating motion from conventional control inputs, the focus was on generating natural and context-aware motions that matched the speaker’s intent and utterances during conversation. In that sense, it approached the problem from a somewhat different direction.

Acknowledgements
This may be a somewhat unusual way to begin a post, but I wanted to start this one with acknowledgements. I think it is easier to explain why this project began and what problem it was trying to solve if I briefly talk about the company situation at the time, at least to the extent that was publicly discussed. Also, I received so much support and consideration throughout the process that starting with acknowledgements simply felt right.
From 2022 to 2023, when I joined NCSOFT, the CRO leading the AI Center was my advisor, Jehee. During that period, the AI organization was heavily focused on building a Digital Human. From NLP to Vision and finally Graphics, multiple teams were moving toward a single goal: Digital Human. The role of our team was to make the character generate natural gestures during conversation. NC Digital Human Yes, the paper I wrote was essentially the gesture generation component of a much larger project, reorganized into paper form. However, although the project itself ended in 2023, the paper was only published near the end of 2024. There was a background related to the company direction behind this delay.
In 2024, NC shifted its direction more strongly toward profitability. However, this was somewhat different from Jehee’s philosophy at the time as CRO that “research groups should pursue long-term research rather than short-term profit.” Since the directions no longer aligned, Jehee stepped down from the CRO position and remained as an advisor, while the AI organization shifted toward projects more directly tied to business value. Article on NCSOFT research reorganization
Under those circumstances, writing a paper became almost impossible. Revisiting a finished project and turning it into a paper could itself become a burden from the organization’s perspective. The entire company was moving toward profitability, while I was effectively looking backward at an already completed project. Another issue was the lack of someone to guide the paper writing itself. The technical side was not the main problem since I had already led much of the work and obtained the results. The harder part was turning those results into an actual paper. Even now I still struggle with paper writing, but back then it was honestly much worse. Looking back at the early drafts today makes me want to close my eyes.
The person who gave me a lot of support here was our team leader at the time, Manager C. Writing a paper could potentially expose parts of company resources externally, so it was naturally a sensitive matter. Even so, Manager C gave me the time and flexibility needed to work on it. Jehee, who was serving as an advisor at the time, also kindly reviewed the paper. He even came in on weekends and worked through the paper with me. He did not need publication records, and there was no extra compensation for spending weekends on this. He simply gave his time to help his student.
Even though the team was going through a difficult period, Manager C still supported me, and Jehee guided the paper without asking for anything in return. Because of them, this paper was able to come into the world. I sincerely thank both of them.
What Kind of Gestures Should We Create?
Now I want to talk about the philosophy behind this paper. Since our company was a game company, the quality bar for graphics was very high. We collaborated with several technical artists, and in the end, appearance was the most important factor. Because of that, there were many different opinions on what gestures should look like. Some conservative opinions suggested simply playing motions where the character occasionally nods and raises an arm once in a while. The idea was to use motions similar to those commonly found in games. In this view, the priority was not how well the gestures matched the speech, but rather preventing awkward or distracting movements during interaction with the Digital Human as much as possible. To move beyond these opinions and make our gesture module actually usable, the most important point was ultimately generating natural motions that did not feel awkward. In particular, if the gesture quality ended up in an ambiguous middle ground, it could easily fall into the Uncanny Valley, so this was the aspect we paid the most attention to.
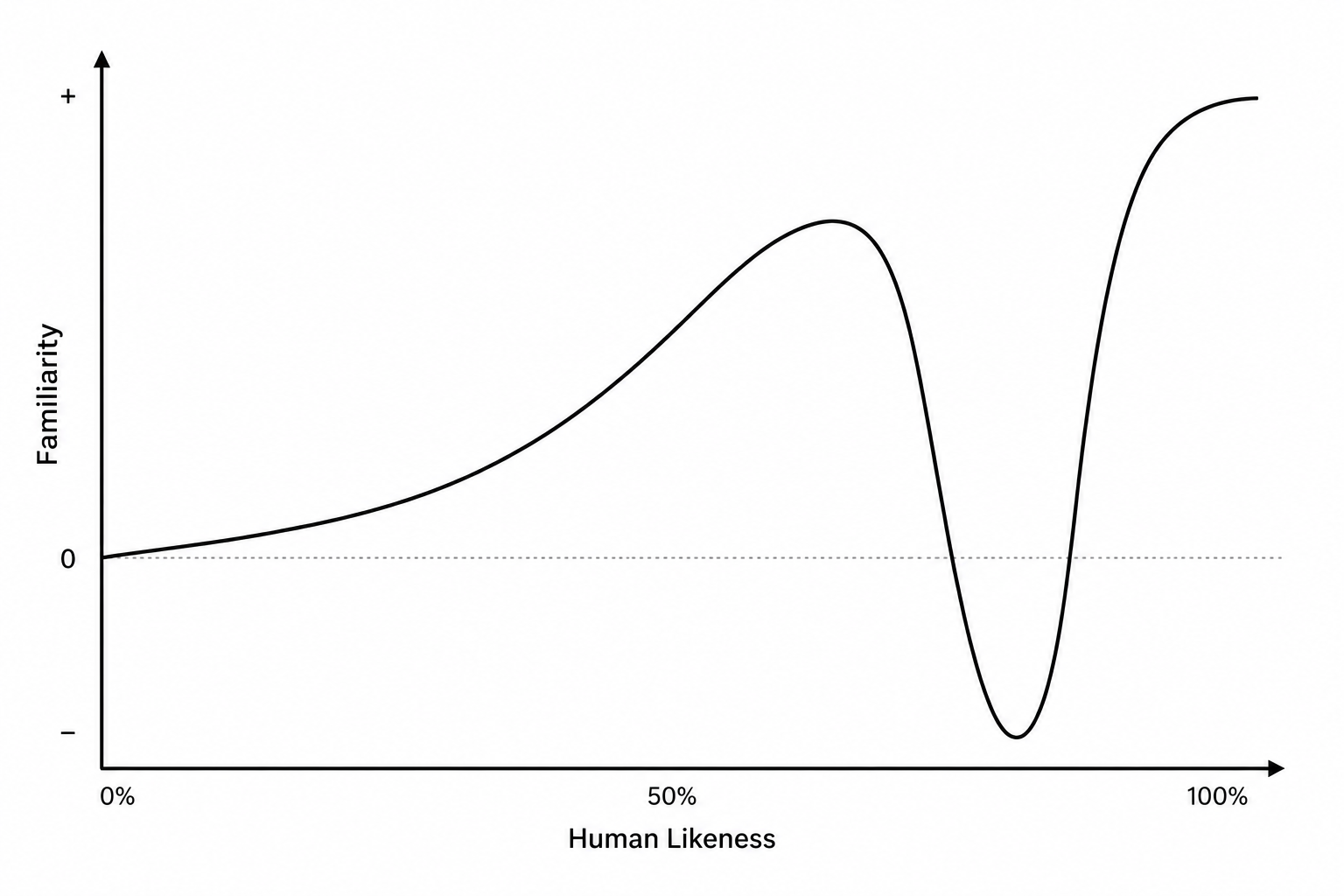
The second requirement was real-time performance. If the goal of gesture generation had simply been to automatically generate gesture presets for games, then it would not have mattered much whether gesture generation took several seconds. However, our goal was gesture generation for a multimodal agent interacting in real time. Since it had to operate as part of a much larger system, we could only spend at most a few hundred milliseconds to generate roughly ten seconds of gestures.
Finally, the gestures had to resemble how humans actually behave. If the gestures simply waved hands around in rhythm without meaning, people interacting with the system might start feeling that these motions were not conveying any intent and were merely prerecorded presets, like something from a video game. On the other hand, if every gesture matched the literal meaning of every utterance, the result would become almost sign-language-like, expressing every sentence explicitly, which would also feel unnatural. In the end, implementing “human-likeness” required first understanding how people actually move before designing the research itself.
Gesture Matching vs. Gesture Learning
Most gesture research I found as references at the time followed learning-based approaches. A representative example was Gesticulator. Since building rule-based gestures corresponding to sound or text is usually very difficult, the idea was to leave the problem to a neural network. It was a very effective approach, and I think the advantages it brought were significant. It could generate plausible gestures in real time regardless of what voice or text was given. The problem was that the quality of the generated gestures was not satisfactory by game industry standards. To animators, the motions looked like arms waving meaninglessly in rhythm. Real people extend their arms or point with their fingers to convey specific meanings, but these motions were mostly blurred away. As a result, the gestures looked plausible at first glance, yet still felt like repetitive arm waving in the air.
Against this trend, there was also a paper that proposed a more classical approach instead of a learning-based one: A Motion Matching Framework for Controllable Gesture Synthesis from a Speech. The idea was to compute pose similarity rankings and audio similarity rankings separately from a database given the input audio and previous motion history, then select the motion with the lowest combined rank. Since each feature used a different measure, instead of tuning weights between feature costs, the method independently ranked them and simply summed the rankings. It was simple but effective. Since motions were directly matched from a database, the resulting gestures looked like something an actual person would do. The downside was computational cost. Because it relied on computing and combining rankings, running it in real time was almost impossible.
Learned Gesture Generator
The result of combining the strengths of these two approaches became the Learned Gesture Generator. The idea started from a simple question: “What if Motion Matching could be implemented in a learning-based way?” The initial structure was quite similar to Daniel Holden’s Learned Motion Matching. The Decompressor, which reconstructs encoded features back into the original motion, and the Stepper, which advances features over time, were implemented in a way similar to Learned Motion Matching. The difference appeared in the Projector. In the gesture case, the latent representation had to encode both audio features and pose features simultaneously, so this part had to be solved technically. For example, even when starting from the same pose, different speech content should lead to different gestures.
Another challenge was that defining the loss function was extremely difficult. In Learned Motion Matching, the control input itself is related to pose, making it relatively straightforward to construct the loss function. However, audio features in gesture generation are difficult to explicitly connect to poses. Because of this, we approached the problem not as a regression task but from the perspective of generative modeling. The idea was that if a GAN could learn to generate plausible Pose + Audio feature combinations close to the latent distribution of real data, then the generated gestures would also appear somewhat human-like. As can be seen in the results, it was able to generate very natural gestures in real time.
Introducing LLMs
The Learned Gesture Generator was clearly able to produce natural gestures, but it could not generate gestures that matched meaning. Many previous works simply used text as neural network input and expected semantically appropriate motions to emerge automatically. However, the relationship between gestures and speech is extremely complex and subtle. People do not always perform a specific gesture for a specific word as if following a rule. Even for the same word, gestures are influenced by many factors such as importance within the utterance, context, and overall conversation flow. Because of this, making a neural network decide semantically appropriate gestures was a very difficult problem.
Humans, however, can roughly tell what kind of gesture should appear in a piece of text using common knowledge alone. Similar to stage directions in a script, gestures can be inserted at specific points. The important part is that these directions should not be determined sentence by sentence. Instead, they should consider the overall context, adjusting timing and frequency to maintain a natural conversational flow. Humans can do this when writing dialogue. Now let us flip the perspective. Our gesture module was going to be part of a larger Digital Human system. That means there already existed a core LLM module capable of generating dialogue while remembering conversation turns. Then why not let the LLM determine gestures using common knowledge, instead of searching for semantically meaningful gestures directly from a gesture-audio dataset?
We captured commonly used gestures with clear meanings, which we called Symbolic Gestures, as presets and passed that list to the LLM. While generating dialogue, the LLM also generated instructions describing which gesture should be used. We then played those gestures at appropriate timings. In simple terms, the instruction-based gestures were inserted first, while the Learned Gesture Generator filled in the remaining intervals naturally. This resulted in a gesture generator that worked in real time, preserved human-likeness, conveyed meaning, and reached a level of quality that would be acceptable even in a game company.
Using Social Science in Computer Science
To be honest, it is difficult for engineers to know what makes a gesture feel natural. Explaining it logically is even harder. Even if I personally feel that a gesture looks natural, someone else may disagree. In particular, while working on the project, I needed solid justification to convince people in higher positions, and literature studies played an important role here. Different people also had different ideas about what natural gestures should look like, so in this part I needed enough evidence to confidently push our direction. In that sense, introducing theories from social science to support our approach became important.
The idea of using an LLM to generate instructions came from reading papers by Paul Ekman. Starting from Types of Gestures, which categorizes gestures into rhythm-based and meaning-based ones, and then studying the finer classifications of semantic gestures, I was finally able to form a blueprint of what kinds of gestures we should create and what gestures we should capture. One of my personal beliefs is that good research starts from knowing what you actually want to build, and social science helped me draw that picture.
Capturing Gestures Is Difficult
Let us assume that we want to collect gesture data. Should we ask actors to perform gesture scenarios explicitly, or should we let gestures emerge naturally through conversation? Gestures while standing, sitting, or resting arms on a desk are all different. Then what kind of situation should we assume? What scenarios should we prepare to capture natural gestures? What directions should we give actors so that meaningful gestures actually appear? Looking at publicly available gesture datasets, I think there are clear signs that people have thought about these issues, but they were not easy to solve. Most datasets assume situations such as giving speeches or talking at length about oneself. It is much harder to capture listening motions, thinking behaviors, or natural interruption gestures. Also, many people feel uncomfortable talking about themselves for a long time, and during actual recording sessions, many actors struggled to continue once a single utterance exceeded about two minutes.
The approach I chose was simple. We recorded every situation we could think of and selected the highest-quality core data as the main dataset. I will stop here because describing the exact method could touch confidential details. A simplified protocol is written in the paper. Conceptually, though, my view is consistent with what I discussed above. Even the same person changes gesture styles depending on the situation. Because of that, I would recommend first defining the specific type of gestures you want and then designing the motion capture process around that target.
Closing Thoughts
Before this project, I had rarely experienced collaboration at this scale, so being responsible for a part of such a large project was a very valuable experience for me. There were times when communication was difficult, and moments when different people wanted different things, which was not always easy. Still, I think those experiences became an important source of growth for me.
There are actually many stories I could not include here. Blending methods for natural motion, designs for improving Inertialization, and many others. This project was also the first time I realized how broad the field of kinematic motion research really is. Before that, most of my focus had been on physics-based motion. Through this project, I was able to see the field from a much wider perspective.
I also remember working on many industry-academia projects during this period. We explored topics such as generating diverse idle motions from limited datasets and Skinned Motion Retargeting, among many others. Some of those projects eventually became papers as well. From the company side, leading many collaborative projects was also a new experience for me.
I hope this field continues to grow. Personally, I think gesture research is still in its infancy. My point is that research should not become papers for the sake of papers, but should start from understanding how people actually move. Some works approach the field by feeding data into networks, modifying architectures slightly, and applying new theories without much understanding of the resulting motion itself. That can still be effective, of course. But in the end, I think it becomes difficult to properly understand and evaluate the actual results. Research should first ask what kind of thing we want to create, and then build methods around that goal.
Finally, when I left NC AI, I handed over my gesture-related research to the team working on VARCO SyncFace. The original goal of that team was to provide a service for generating facial motions, mainly lip-sync motions aligned with speech. However, there was also a demand for matching gestures, so I passed all of my related work to them. I hope that one day a service including my research will come into the world, and I wish the best for NC AI.