Trivia: Body Gesture Generation for Multimodal Conversational Agents
오랜만에 블로그로 돌아왔다. 논문 한 편을 제출하고 나니 이제야 조금 여유가 생겨서 다시 블로그를 써보려고 한다. 늘 그렇듯 이번 글도 의식의 흐름대로 적었다. 읽다가 갑자기 논리가 튄다거나, 무슨 말인지 잘 이해가 안 되는 부분이 있다면 개인적으로 물어봐도 좋다. 기꺼이 답해줄 생각이다.
이번에는 2024년 SIGGRAPH ASIA에 발표되었던 Body Gesture Generation for Multimodal Conversational Agents 논문의 뒷이야기를 해보고 싶다. 사실 이 이야기는 블로그를 시작하자마자 가장 먼저 쓰고 싶었던 주제였다. 다만 이 연구가 내가 이전에 다니던 회사에서 진행했던 프로젝트였던 만큼, 혹시라도 confidential한 내용을 이야기하게 될까 조심스러워서 이제야 글을 쓰게 되었다. 최대한 논문에 들어간 내용의 디테일 정도만 다루면서 뒷이야기를 풀어보려 한다. 민감할 수 있는 부분은 언론에 공개된 자료를 레퍼런스로 달아, 외부 공개된 내용을 바탕으로 작성했다는 점도 함께 밝힌다.
아마 몇몇 사람들, 어쩌면 꽤 많은 사람들이 이 논문을 보고 “음성 입력을 넣으면 모션이 나오는 네트워크를 만든 연구” 정도로 받아들였을 수도 있다. 심지어 이 논문 자체를 컴퓨터 애니메이션 분야의 논문으로 보지 않는 사람들도 있었던 것 같다. 하지만 내가 말하고 싶은 것은, 이 연구는 기존 애니메이션 연구에서 비교적 깊게 다뤄지지 않았던 문제를 풀어보려는 시도였다는 점이다. 일반적인 컨트롤 입력으로 모션을 생성하는 것이 아니라, 대화 상황 속에서 화자의 발화와 의도에 맞춰 자연스럽고 맥락에 맞는 동작을 생성하는 문제를 다루고 있었다는 점에서 조금 다른 방향의 연구였다.

감사 인사
조금 특이한 방식이지만, 이 글은 감사 인사로 시작해보려 한다. 당시 회사 상황을 언론에 공개된 수준에서 아주 조금 이야기해야 이 프로젝트가 왜 시작되었는지, 그리고 무엇을 풀고 싶었던 프로젝트였는지를 설명하기 쉬울 것 같다. 그리고 그 과정에서 정말 많은 배려와 도움을 받았기 때문에, 이 글은 감사 인사로 시작하는 것이 맞다고 생각했다.
내가 NCSOFT에 합류했던 2022년부터 2023년까지 AI 센터를 이끌던 CRO는 내 지도교수님이셨던 이제희 교수님이었다. 그 시기 AI 조직은 Digital Human을 만드는 데 많은 역량을 쏟고 있었다. NLP부터 Vision, 그리고 마지막에 보이는 Graphics까지, 여러 팀이 하나의 Digital Human이라는 목표를 향해 달려가고 있었다. 우리 팀이 맡은 역할은 이 캐릭터가 대화 상황에서 자연스러운 제스처를 생성할 수 있도록 만드는 일이었다. NC Digital Human 그렇다. 내가 쓴 논문은 거대한 프로젝트 중 일부였던 제스처 생성 파트를 논문 형태로 정리한 작업이었다. 다만 프로젝트 자체는 2023년에 끝났는데 논문 발표는 2024년 말이 되어서야 이루어졌다. 여기에는 회사의 방향성과 관련된 배경이 있었다.
2024년, NC는 회사 방향을 보다 강하게 수익 중심으로 전환했다. 하지만 이는 당시 CRO셨던 이제희 교수님의 “리서치 그룹은 단기적인 수익보다 장기적인 연구를 해야 한다”는 철학과는 조금 결이 달랐다. 결국 방향성이 달랐기에 이제희 교수님은 CRO 직을 내려놓고 고문으로 재직하시게 되었고, AI 조직 역시 수익성과 연결되는 프로젝트 중심으로 방향을 바꾸게 되었다. NCSOFT 리서치 조직 개편 기사
그런 상황이 되다 보니 논문을 쓴다는 것은 거의 불가능에 가까운 일이었다. 이미 끝난 프로젝트를 다시 꺼내 논문으로 만드는 일은 내가 속한 조직 입장에서도 부담이 될 수 있었다. 회사 전체가 수익을 향해 달려가는 상황에서, 혼자 과거 프로젝트를 붙들고 역주행하는 모양새가 될 수도 있었기 때문이다. 또 다른 문제는 논문 지도를 받을 사람이 없다는 점이었다. 기술적인 부분 자체는 내가 주도해서 결과를 냈기 때문에 큰 문제는 아니었다. 오히려 더 어려웠던 것은 그 결과를 “논문”으로 쓰는 일이었다. 지금도 논문 작성은 어려운데, 당시에는 정말 심했다. 지금 그때 초안을 다시 보면 너무 부족해서 눈을 감고 싶어질 정도다.
여기서 큰 배려를 해주신 분이 당시 팀장님이셨던 C님이었다. 논문을 쓴다는 것 자체가 회사 리소스 일부를 외부에 공개하는 일이 될 수도 있어 조심스러운 상황이었지만, 논문을 작성할 수 있도록 배려해주셨다. 그리고 고문으로 계시던 이제희 교수님께서도 흔쾌히 논문을 봐주셨다. 주말에도 직접 나오셔서 함께 논문을 검토해주셨다. 논문 실적이 필요한 상황도 아니셨고, 주말에 나온다고 별도의 보상이 있는 것도 아니었는데 제자를 위해 시간을 써주셨다.
팀이 쉽지 않은 상황이었음에도 배려해주신 C님, 그리고 아무 조건 없이 논문 지도를 해주신 이제희 교수님 덕분에 이 논문은 세상에 나올 수 있었다. 두 분께 진심으로 감사드린다.
어떤 제스처를 만들 것인가?
이제 본격적으로 이 논문의 철학에 대해서 이야기해보고자 한다. 우리 회사가 게임 회사다보니 그래픽에 대한 기준이 매우 높았다. 몇몇 테크니컬 아티스트와 협업하기도 했으며, 결국 보이는 것이 가장 중요한 요소였다. 때문에 제스처가 어떤 형태여야 하는지에 대한 의견도 매우 다양했다. 보수적인 의견 중에는 그냥 고개만 까딱거리다가 팔을 한 번씩 드는 동작만 재생하자는 의견도 있었다. 전형적인 게임에 들어가는 모션을 넣자는 방향이다. 여기서는 말과 제스처가 얼마나 잘 맞느냐가 기준이 아니라, 디지털 휴먼과 소통하는 과정에서 동작이 어색하거나 거슬리는 것을 최대한 방지하는 것이 최우선이라는 관점이었다. 이런 의견을 이겨내고 우리의 제스처 모듈을 실제로 쓰게 만들려면, 결국 어색하지 않은 자연스러운 동작을 생성하는 것이 가장 중요한 포인트였다. 특히 제스처의 퀄리티가 애매하면 자칫 Uncanny Valley에 빠질 수 있기 때문에, 이 부분을 가장 많이 신경 썼다.
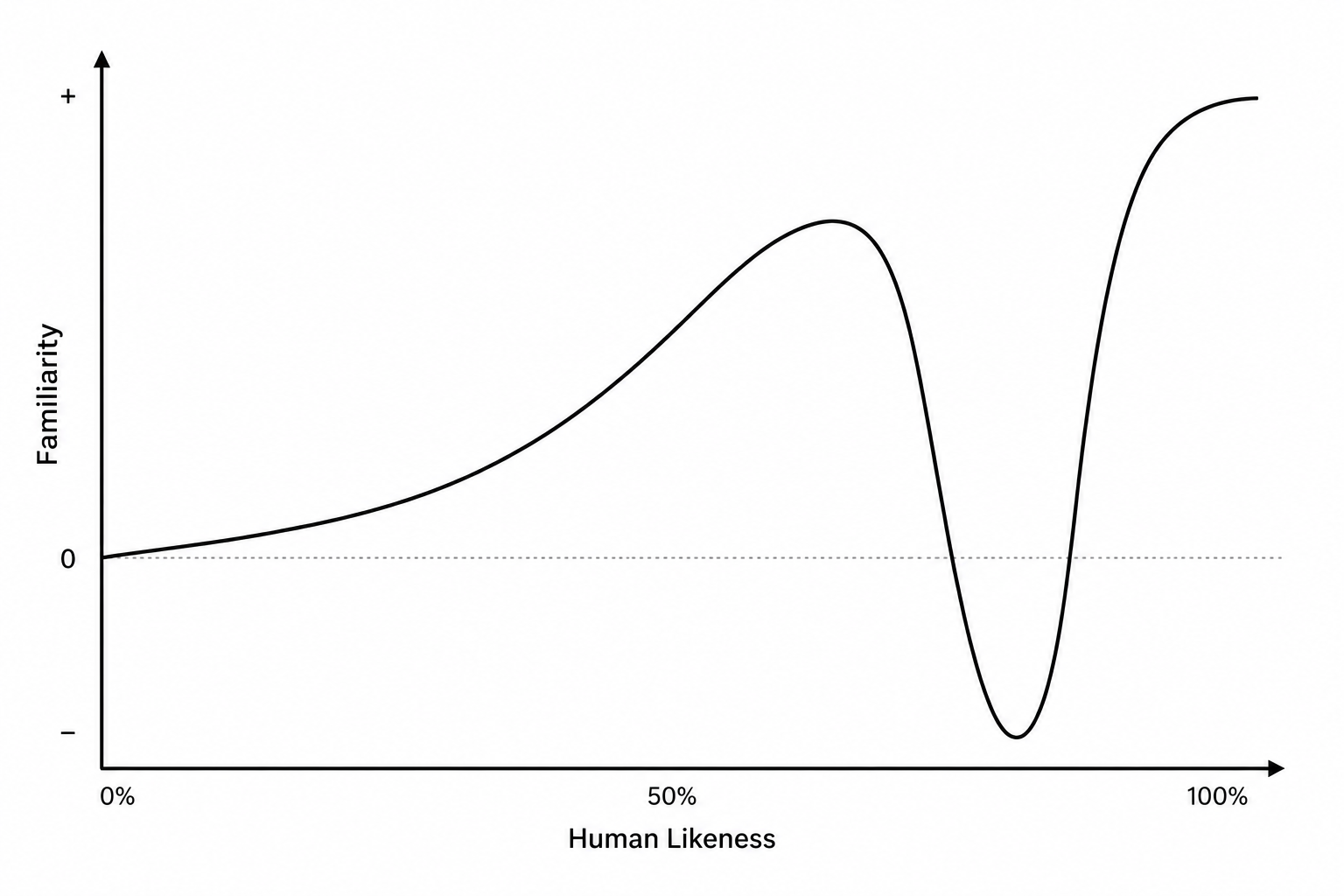
둘째는 실시간성이다. 만약 제스처 생성의 목적이 게임에 들어갈 제스처 프리셋을 자동 생성하는 것이었다면, 제스처 생성에 몇 초가 걸리든 큰 문제는 없었을 것이다. 하지만 우리의 목표는 실시간으로 소통하는 멀티모달 에이전트를 위한 제스처 생성이었다. 거대한 시스템 안에 들어가는 만큼, 약 10초 정도의 제스처를 생성하는 데 최대 수백 ms 정도만 사용할 수 있었다.
마지막으로 사람과 비슷한 제스처를 해야 했다. 제스처가 의미 없이 리듬에만 맞춰 손을 휘적거리기만 한다면, 대화를 하다 보면 이 동작이 특정 의미를 전달하는 것이 아니라 컴퓨터 게임처럼 미리 녹화된 프리셋이 아닌가 하는 의심이 들게 된다. 반대로 모든 말의 의미에 맞춰 제스처를 생성하면 거의 수화처럼 모든 발화를 표현하게 될 것이고, 이것 역시 어색할 것이다. 결국 “사람다움”을 구현하려면 실제 사람이 어떻게 움직이는지를 먼저 이해한 뒤 연구가 들어가야 했다.
Gesture Matching vs. Gesture Learning
그 당시 레퍼런스로 찾았던 대다수의 제스처 연구는 learning-based 접근이었다. 대표적으로 Gesticulator가 있었는데, 보통 sound나 text에 대응되는 제스처를 rule-base로 만드는 것은 매우 까다롭기 때문에 이를 network에 맡기는 방식이었다. 굉장히 효과적인 접근 방식이고, 이 방식이 가져다주는 장점도 매우 크다고 생각한다. 어떤 목소리가 들어오든, 어떤 텍스트가 들어오든 그럴듯한 제스처를 실시간으로 생성할 수 있었기 때문이다. 문제는 생성된 제스처의 퀄리티가 게임 회사의 기준에서 만족스럽지 않았다는 점이다. 애니메이터들의 눈에는 리듬에 맞춰 의미 없이 팔을 휘적거리기만 하는 동작처럼 보였다. 실제 사람은 특정 의미를 전달하기 위해 팔을 뻗거나 손가락으로 포인팅을 하게 되는데, 이런 동작들은 대부분 뭉개지고, 결과적으로는 그럴듯해 보이지만 공중에서 팔을 반복적으로 휘젓는 느낌이 들 수밖에 없었다.
이러한 흐름 속에서 learning 기반 접근을 거슬러 비교적 고전적인 방법을 제시한 논문도 있었다. A Motion Matching Framework for Controllable Gesture Synthesis from a Speech에서는 주어진 오디오와 이전까지 수행하던 모션에 대해 DB에서 각각 포즈 유사도와 오디오 유사도의 랭킹을 계산한 뒤, 두 랭킹의 합이 가장 낮은 모션을 선택하는 아이디어를 제안했다. 각 feature의 measure 방식이 다르다 보니 두 feature cost의 weight를 튜닝하는 대신, 각각 독립적으로 계산한 랭킹을 더해버리는 매칭 방식이었다. 심플하지만 효과적인 접근이었고, 모션을 DB에서 직접 매칭하기 때문에 실제 사람이 할 법한 동작이 그대로 나왔다. 다만 단점은 랭킹을 계산하고 더하는 방식이다 보니 computation cost가 컸고, 이를 실시간으로 수행하기는 거의 불가능했다.
Learned Gesture Generator
이 두 방법의 장점을 합쳐 나온 것이 Learned Gesture Generator이다. 아이디어는 “Motion Matching을 learning-based 방식으로 구현하면 되지 않을까?”에서 출발했다. 초기에 생각한 구조는 Daniel Holden의 Learned Motion Matching과 꽤 비슷했다. Encoding된 feature를 다시 원본 모션으로 복원하는 Decompressor와, feature를 시간에 따라 진행시키는 Stepper는 Learned Motion Matching과 유사한 방식으로 구현했다. 다만 Projector를 구현하는 과정에서는 차이가 있었다. 제스처의 경우 audio feature와 pose feature를 동시에 표현할 수 있는 latent로 encoding해야 했기 때문에 이 부분을 기술적으로 해결해야 했다. 예를 들어 같은 포즈에서 시작하더라도 말하는 내용이 다르면 다른 제스처가 나와야 하기 때문이다.
여기서 또 다른 문제는 loss function을 구현하기가 매우 어렵다는 점이었다. Learned Motion Matching에서는 control input 자체도 pose와 관련되어 있기 때문에 비교적 자연스럽게 loss function을 구성할 수 있다. 하지만 제스처의 audio feature는 explicit하게 포즈와 연결하기가 어렵다. 그래서 우리는 이 문제를 regression 문제가 아니라 generative model의 관점에서 접근했다. GAN을 이용해 Pose + Audio feature를 원래 데이터 분포의 latent와 비슷하게 그럴듯하게 생성할 수 있는 네트워크를 학습시킨다면, 결국 생성된 제스처 역시 어느 정도 사람처럼 보일 것이라고 생각했다. 결과는 다들 볼 수 있듯, 실시간으로 매우 자연스러운 제스처를 생성할 수 있었다.
LLM을 도입하다.
Learned Gesture Generator는 분명 자연스러운 제스처를 만들었지만, 의미에 맞는 제스처를 만들지는 못했다. 기존의 많은 연구들은 text를 neural network input으로 넣고, 알아서 의미에 맞는 동작이 나오기를 기대했다. 하지만 제스처와 말 사이의 관계는 정말 복잡하고 미묘하다. 사람은 규칙처럼 항상 특정 단어에 특정 제스처를 하지는 않는다. 같은 단어라도 해당 발화에서의 중요도, 상황, 대화 맥락 등 여러 요소가 복합적으로 작용해서 제스처가 결정된다. 그렇기 때문에 우리가 만드는 neural network가 의미에 맞는 제스처를 결정하도록 만드는 것은 매우 어려운 문제였다.
하지만 사람은 대충 common knowledge만 있어도 주어진 글에서 어떤 제스처가 들어가야 할지 어느 정도 안다. 마치 대본에 지시문을 넣듯, 특정 포인트에 제스처를 삽입할 수 있다. 중요한 것은 이 지시문이 각 문장을 따로 보고 들어가는 것이 아니라, 전체 문맥을 보면서 빈도와 타이밍을 조절해 대화 흐름을 자연스럽게 만들어야 한다는 점이다. 사람은 대화 내용을 써 두면 이런 작업을 할 수 있다. 여기서 생각을 뒤집어보자. 우리의 제스처 모듈은 거대한 Digital Human 시스템의 일부로 들어간다. 즉, 이미 턴을 기억하며 대화를 생성하는 코어 LLM 모듈이 존재한다는 뜻이다. 그렇다면 특정 의미를 가진 제스처를 gesture-audio dataset에서 찾는 것이 아니라, LLM이 common knowledge를 바탕으로 결정하게 만들 수 있지 않을까?
우리는 일반적인 대화에서 자주 쓰이고 의미가 명확한 제스처들(Symbolic Gesture)을 프리셋 형태로 캡처했고, 그 리스트를 LLM에 넘겼다. LLM은 발화를 생성하는 동시에 해당 발화에 어울리는 지시문도 함께 전달했고, 우리는 그 gesture를 적절한 타이밍에 재생했다. 간단히 말하면, 지시문 기반 gesture를 먼저 재생하고 Learned Gesture Generator가 나머지 구간을 자연스럽게 생성하도록 모듈을 구성했다. 그렇게 해서 실시간으로 동작하면서도 사람다움을 유지하고, 의미 전달까지 가능한, 게임 회사에서 사용해도 손색없는 수준의 제스처 생성기가 만들어질 수 있었다.
컴퓨터공학에서 사회과학을 이용하는 법
사실 어떤 제스처가 자연스러운지 공돌이들이 알기는 어렵다. 그걸 논리적으로 설명하기는 더더욱 어렵다. 내가 만든 제스처가 자연스럽다고 느껴도, 누군가는 그렇게 느끼지 않을 수 있다. 특히 프로젝트를 진행하면서 상위 직책자들을 설득하려면 근거가 필요했고, 문헌 연구는 여기서 중요한 역할을 했다. 상위 직책자들도 어떤 제스처가 자연스러운지에 대해 각자 생각이 달랐기 때문에, 이 부분에서는 내가 확실한 근거를 갖고 밀어붙여야 했다. 그런 의미에서 사회과학의 이론을 도입해 우리의 방향을 뒷받침하는 것이 중요했다.
LLM을 이용해 지시문을 생성하겠다는 아이디어는 Paul Ekman의 논문들을 읽으면서 나오게 되었다. Types of Gestures에서 제스처가 리듬과 의미로 나뉜다는 점에서 출발해, 의미를 표현하는 제스처의 세부 분류까지 공부하고 나서야 어떤 제스처를 만들어야 하는지, 또 어떤 제스처를 캡처해야 하는지에 대한 청사진이 그려졌다. 뭘 만들어야 할지 알아야 좋은 연구가 나올 수 있다는 것이 내 지론이고, 사회과학은 그 그림을 그리는 데 큰 도움을 줬다.
제스처 캡처는 어려워
제스처 데이터를 얻는다고 가정해보자. 제스처를 하는 상황을 연기하게 할 것인가, 아니면 자연스러운 대화 속에서 풀어가게 할 것인가? 서 있을 때의 제스처, 앉아 있을 때의 제스처, 책상처럼 팔을 둘 곳이 있을 때의 제스처는 모두 다르다. 그렇다면 어떤 상황을 가정해야 할까? 자연스러운 제스처를 촬영하려면 어떤 시나리오를 줘야 하고, 배우에게 어떤 디렉션을 줘야 제스처가 제대로 캡처될까? 사실 공개된 제스처 데이터셋을 보면 이런 고민을 한 흔적은 보이지만, 쉽게 풀지는 못한 것 같다. 대부분의 데이터는 웅변을 하거나 자신의 이야기를 길게 하는 상황을 가정하고 제스처를 캡처하는 경우가 많다. 듣는 모션이나 고민하는 모습, 자연스럽게 말을 끼어드는 제스처를 캡처하기는 어렵다. 또한 본인의 이야기를 길게 하는 것 자체에 부담을 느끼는 사람도 많고, 실제로 촬영해보면 한 발화가 2분을 넘어갈 때 무슨 이야기를 해야 할지 어려워하는 배우님들도 많았다.
내가 택한 방법은 심플했다. 모든 상황을 다 찍어보고, 그중 퀄리티가 가장 좋은 핵심 데이터를 main으로 사용했다. 내가 사용한 방법을 자세히 적으면 confidential한 내용을 이야기하게 될 수도 있기 때문에 여기서는 말을 줄이겠다. 다만 간단한 프로토콜은 논문에 적어두었다. 컨셉적으로만 내 생각을 공유하자면, 위에서 적은 내용과 일맥상통한다. 한 사람이라도 상황에 따라 제스처의 형태가 달라진다는 점을 염두에 두고, 원하는 제스처의 형태를 구체적으로 구상한 뒤 모션 캡처에 들어가기를 권장한다.
마치면서
이 프로젝트를 진행하기 전까지는 협업을 이렇게 크게 해본 적이 거의 없었는데, 정말 거대한 프로젝트의 일부를 맡아 진행한다는 값진 경험을 할 수 있었다. 때로는 소통에 어려움을 겪기도 했고, 서로 원하는 방향이 달라 힘들었던 순간도 있었지만, 그 경험 자체가 나에게는 꽤 큰 자양분이 된 것 같다.
여기에 다 하지 못한 이야기도 사실 많다. 자연스러운 모션을 위한 블렌딩 방법, Inertialization을 고도화하기 위한 설계 등등. 사실 kinematic motion 연구 분야가 이렇게까지 넓은지 이 프로젝트를 하면서 처음 알게 된 것 같다. 그전까지는 physics-based motion 쪽에 시야가 많이 맞춰져 있었다면, 이 프로젝트를 통해 조금 더 넓은 관점에서 이 분야를 바라볼 수 있게 되었다.
프로젝트를 진행하면서 산학과제도 정말 많이 했던 기억이 난다. 한정된 데이터셋으로 다양한 idle motion을 만드는 연구, 제스처가 몸을 뚫으면 안되니 Skinned Motion Retargeting 연구 등 꽤 많은 과제를 진행했고, 몇몇 산학과제는 실제 논문 성과로 이어지기도 했다. 회사 입장에서 산학과제를 많이 이끌어본 경험 자체도 꽤 신선했다.
나는 이 분야 연구가 앞으로 더 발전했으면 한다. 개인적으로 제스처 연구는 아직 걸음마 단계라고 생각한다. 요는 논문을 위한 논문이 아니라, 실제 사람이 어떻게 움직이는지를 고민하는 방향으로 연구가 진행되었으면 한다. 몇몇 논문들은 이런 이해 없이 데이터를 넣고, 네트워크를 조금 바꾸고, 새로운 이론을 적용해보는 정도로 접근하는 경우도 있다. 물론 그것도 효과적일 수는 있다. 하지만 결국 결과물 자체에 대한 제대로 된 이해와 평가를 하기 어렵다고 생각한다. 무엇을 만들고 싶은지를 먼저 고민하고, 그 목표에 맞춰 연구가 진행되었으면 한다.
끝으로, 내가 NC AI를 퇴사할 때 VARCO SyncFace를 운영하는 팀에 제스처 관련 연구를 인수인계하고 나왔다. 원래 해당 팀의 목표는 발화에 맞는 얼굴 모션, 주로 립싱크를 생성하는 서비스를 만드는 것이었지만, 거기에 맞는 제스처도 필요하다는 요구가 있었기에 내가 했던 연구 내용을 전부 전달하고 왔다. 언젠가 내 연구까지 포함된 하나의 서비스가 세상에 나오길 바라며, NC AI에도 행운이 있기를 바란다.